ML for Predictive Maintenance
Comparison of machine learning models for predictive maintenance in manufacturing
Github repo: https://github.com/yuzom/predictive_maintenance
Introduction
Predictive maintenance is a technique used to determine the condition of an equipment to estimate if a maintenance procedure should be performed on it. Equipment maintenance is key in avoiding equipment failures, which can result in shutdowns of production lines, incurring significant unplanned downtime and cost.
This study compares logistic regression (LR), k- nearest neighbor (KNN), support vector machine (SVM), and decision tree (DT) supervised machine learning (ML) models in their ability to predict machine failures from machine logs.
Motivation
Equipment maintenance takes up a significant portion of the total manufacturing budget. Although the exact estimate varies by literature, the National Institute of Standards and Technology (NIST) has estimated that maintenance costs can range from 15% to 70% of the cost of goods sold (2021).
Out of the three maintenance schedules, predictive maintenance is highly cost effective, with some studies showing a 8-12% saving over preventative maintenance and up to 40% over reactive maintenance (Sullivan et al., 2010).

Data Source
The dataset used is a realistic and synthetic predictive maintenance dataset published to the UC Irvine Machine Learning Repository by Matzka (2020), which consists of 14 dimensions over 10,000 samples.
External Libraries
Several python libraries were used in developing the jupyter notebook code for this study.
NumPy: A fundamental python math package that supports large matrix operations and provides optimized mathematical functions.
Pandas: A data science library that provides data structures such as DataFrames to store, clean, aggregate, and manipulate data in tabular form.
Scikit-learn: An open-source machine learning library that is used to implement the machine learning algorithms in this paper.
Plotnine: A data visualization library adapted from the R package ggplot2 to make box plots during data exploration. Preferred for limited verbosity required in making simple plots.
Seaborn: Another data visualization library suited for creating correlation plots.
Matplotlib: Another data visualization library used to plot decision trees.
Data Exploration
Exploratory data analysis is conducted to learn the shape and format of the dataset. Plotting the class distribution shows that the dataset is highly imbalanced, with only 339 failures and 9661 passes as shown in Fig. 3. Because of this, stratification is used when dividing the dataset into test and training, and the F1 score is used as the primary accuracy metric.

Box plots are plotted to detect any obvious trends in the continuous features. There is a noticeable mean shift between pass and fail for Tool Wear and Torque as shown in Fig. 4, which indicates potential significance.

Feature Selection
A correlation matrix of the scaled dataset is explored. Two pairs of variables are shown to have high correlation to each other:
- Process temperature and air temperature exhibit a positive correlation (R=0.88); this is expected for open-air manufacturing processes where the process is not sealed from the environment.
- Torque and rotational speed exhibit a negative corre- lation (R=-0.88); this is expected as motor RPM and torque have an inverse relationship given constant power.

At this point, both pairs of variables are still kept for analysis because they are not fully correlated (R̸=1). Additionally, domain knowledge suggests that temper- ature is significant in heat sensitive applications such as soldering and welding where a machine may enter an error state if the process temperature falls outside a threshold. Similarly, error states can be triggered if torque and RPM fall outside a threshold.
Dimensionality Reduction
Three methods are used to further analyze the strength of association between the input variables and response: SelectKBest, Extra Trees Classifier, and Mutual Informa- tion Gain. Torque and tool wear were consistently ranked as having high association using all methods as shown in Fig. 6. However, no variables are eliminated because the Extra Trees Classifier used all features for creating its decision trees.

Learning Methods
Logistic regression (LR) is a basic ML algorithm which models the probability of a binary outcome as a function of its input variables. It does this by using the sigmoid function, which takes inputs X and outputs a class probability value p(X).
K-nearest neighbors (KNN) is a simple ML algorithm which predicts a data point’s class by assessing the class of its nearest neighboring points. It does this by calculating the distance between the data point and all training data points. KNN is a simple and intuitive algorithm which works for small to medium sized datasets, but becomes computationally expensive for large datasets.
Support vector machines (SVM) are powerful clas- sifiers used for both sparse data and high dimensional spaces. SVMs work by finding optimal hyperplanes which best discriminate the different classes of data. Similar to DTs, SVMs are well suited for binary classification tasks because both processes revolve around the idea of separating two classes, although both can work for multi-class tasks as well.
Decision trees (DT) are popular for use in clas- sification tasks due to their high interpretability and ability to handle non-linear relationships. DTs work by recursively partitioning the input data based on certain rules until a final prediction is reached.
Hyperparmeter Optimization
All hyperparameters are optimized to reduce the F1 score (3). F1 is chosen over accuracy because the model is highly imbalanced, with 97% of the data points being pass and only 3% being fail. F1 is chosen over precision (1) or recall (2) alone because both false positives and false negatives are detrimental in a manufacturing setting. False positives result in unnecessary maintenance and planned or unplanned downtime. Meanwhile, false negatives result in skipped maintenance, eventually lead- ing to equipment failure and unplanned downtime (RM).
GridsearchCV is used for all hyperparameter opti- mizations because it is exhaustive, meaning it evaluates every combination of hyperparameters specified. Exhaus- tive search is manageable because the dataset is relatively small at 10,000 samples over 6 features.
Results
DT provides the best F1 score of 0.74, followed by KNN, SVM, and LR. DT also balances false positives (precision = 0.74) and false negatives (recall = 0.74) well compared to the other methods which tend to over- predict false negatives (lower recall score), which would result in unnecessary maintenance.
Comparing the default models, DT (0.13s) shows comparable training times with KNN (0.11s) and LR (0.13s), while being almost twice as fast as SVM (0.22s). Note that different hardware environments may result in different runtime and memory usage.
Overall, it is found that hyperparameter optimization is beneficial in achieving higher F1 scores, but the model choice has the most effect.


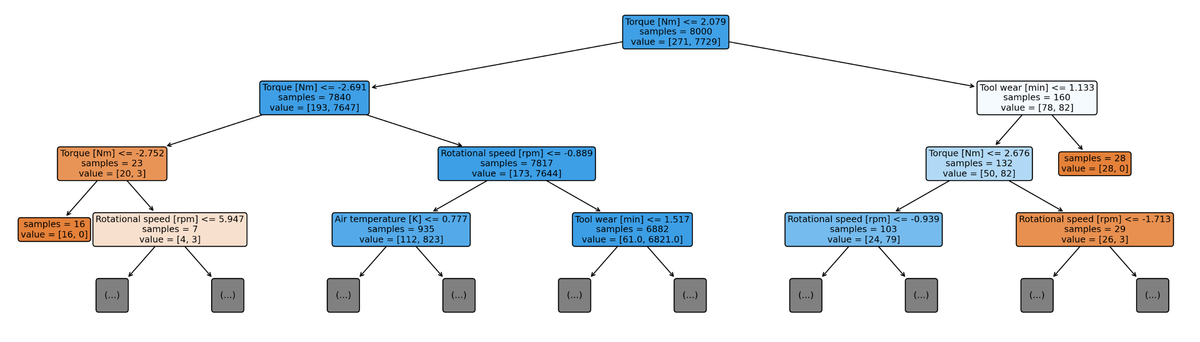
The selected DT graph with actual weights is shown below.
